The dataset for the SSGCI competition has been obtained from a real problem domain of structural pattern recognition: “Document Image Analysis, Recognition and Understanding”. We have selected the “comic book images” as the data source for extracting graph representations, as they have lots of relational information in their content and the various building blocks of the comics exhibits challenging diversity in their shape and attributes while maintaining enough discriminatory information that permits their identification and recognition. The use of comic book images as the source for extracting the graph representations for the competition not only ensures that there is enough variability in the graph dataset, but it also ensures that there isn’t too much variability so that the graph matching becomes too difficult.
The following figure presents some comic book images that have been used for constructing the datasets for the competition.

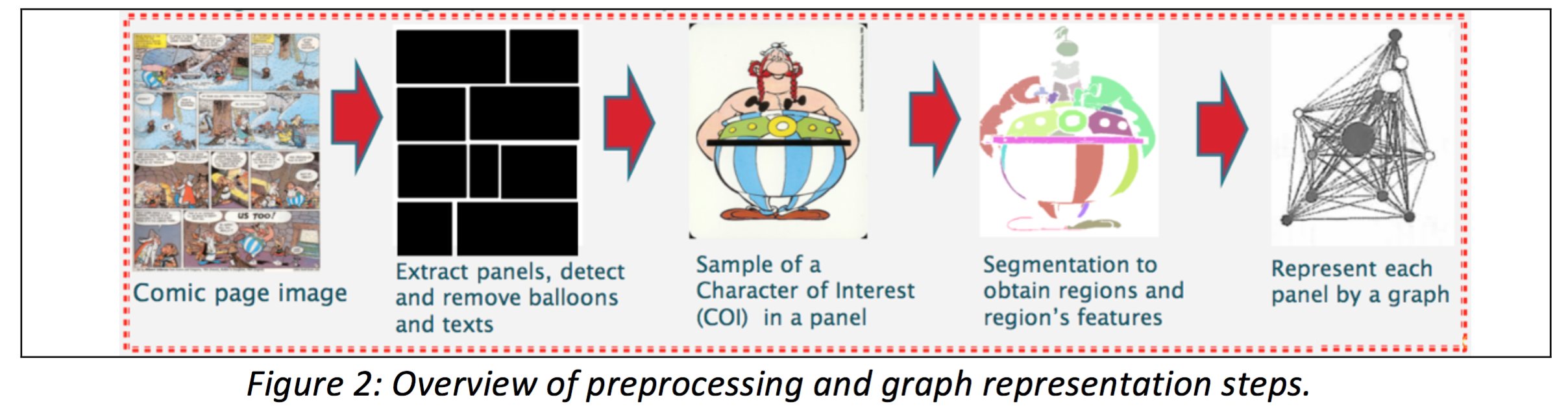
The comic book images are preprocessed (and manually checked) to remove the speech text and to segment the panels in the comic book image. After preprocessing step, each panel in the comic book image is represented by an attributed region adjacency graph (RAG). The nodes of the graph represent the MSER regions in the panel and the arcs of graph represent the spatial relations (based on the proximity) between these MSER regions. The attributes on a node represent the properties of its underlying MSER region and the attributes on an arc represent the properties of the relations between its corresponding underlying MSER regions. The presence of a list of attributes on the nodes and arcs of the graphs in the datasets for the SSGCI competition is very important. However, it is not our goal to propose a best set of attributes for the nodes and arcs of graph representation of comic page images.
Figure 2 presents an overview of the preprocessing step and the representation of a panel in a comic book image by an attributed region adjacency graph.
The attributed region adjacency graphs in the dataset for the SSGCI competition are saved in the GraphML format (details here).
A list of attributes are associated with the nodes of the graphs.
The query graphs represent comic characters in comic book images and are constructed in a similar fashion as detailed above. Some examples of images used for constructing the query graphs in the SSGCI competition datasets are presented below.
 Figure 3: Example of images used for generating query graphs.
Figure 3: Example of images used for generating query graphs.
Ground-truth information about the query graphs (representing the comic characters) is extracted and saved in XML format.
Size of dataset
The dataset is composed of “sample” and “test”. The sample dataset is provided so that the participants can program, adapt and prepare their methods for the competition. The test dataset is used to evaluate the performance of the participant’s methods (details on evaluation protocol here).
Sample dataset
The sample dataset is comprised of the following:
- 50 attributed graphs to form the graph database
- 10 query attributed graphs
- the corresponding ground-truth for the query graphs
Test dataset
The test dataset is comprised of the following:
- 500 attributed graphs in graph database
- 50 query attributed graphs
Dataset will be made publicly available
After the announcement of results at the ICPR 2016 in December 2016, the datasets used for this competition will be made publicly available for the research community, so that the researchers working on the similar research problems can make use of these datasets. This will permit the researchers to benchmark and/or compare their methods, with state of the art works, on SSGCI dataset.